
Does high-speed inference have to be complex? A comparison of TensorRT and ONNXRuntime

ONNXRuntime
ONNXRuntime is a framework based on the onnx model type and allows neural network inference on a few lines. Recently, it has been developed very dynamically towards different inference engines. The table below shows the sample providers and target platforms (you can find the whole and the up-to-date version here).
| Target | Native library | Provider |
|---|---|---|
| NVIDIA Jetson | TensorRT | TensorrtExecutionProvider |
| INTEL NCS2 | OpenVINO | OpenVINOExecutionProvider |
| XILINX FPGAs (preview) | Vitis-AI | VitisAIExecutionProvider |
| Android | NNAPI | OrtSessionOptionsAppendExecutionProvider_Nnapi |
| Apple (preview) | CoreML | OrtSessionOptionsAppendExecutionProvider_CoreML |
Native libraries
Native libraries such as TensorRT for the NVIDIA Jetson series are specifically optimized for the platform. However, it is difficult to write code in them and for a non-experienced person, it may introduce many mistakes. In the TensorRT case for inference you need to:
- create a session and the parser, and then load the engine into the program properly,
- create memory allocations in the host and device,
- bind inputs and outputs,
- manually copy data to the GPU before inference and to the host after the operation.
But just since the alternatives have appeared, why not trust the experienced developers and just use the lines:
import onnxruntime as ort
ort_sess = ort.InferenceSession('model.onnx', providers=['TensorrtExecutionProvider'])
in_names = [inp.name for inp in ort_sess.get_inputs()]
out_name = [output.name for output in ort_sess.get_outputs()]
some_data_output = ort_sess.run(out_name, {in_names[0]: some_data_input})
EDGE AI benchmark
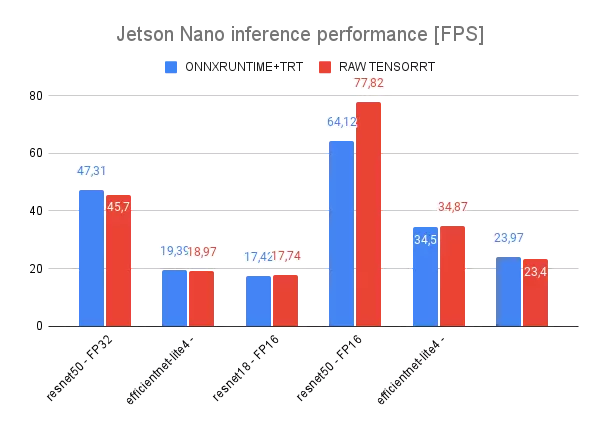
The one-API framework sounds excellent. However, how does it work in practice? It works pretty well! See the following comparison of the performance of ONNXRuntime against TensorRT on popular algorithms for classification tasks on EDGE AI devices: Jetson NX and Jetson NANO.





Comments